Optimiser le scrolling multi-directionnel - Analyse du temps perdu
Pourquoi ?
Pour le moment, nous ne sommes pas en double buffer, ce qui occasionne des artefacts réguliers sur les bords de l'écran. Ce n'est pas grave en soi, on pourrait même les cacher en réduisant la taille visible de l'écran pour la hauteur, ou en élargissant l'écran jusqu'aux bords pour éviter de les voir sur les côtés. Certains jeux s'accomodent plutôt bien de ces défauts car les avantages sont nombreux : On utilise seulement 16k pour l'affichage au lieu de 32k et surtout, il n'y a pas à déplacer deux fois plus de données! En effet, si on se déplace de 2 lignes sur un écran et de 2 lignes sur le second dans la même direction, on doit compenser les 2 lignes précédentes (ce qui fait 4 lignes à scroller).Il n'y a pas de bonne méthode, il y a des choix à faire et des objectifs à atteindre mais vu que la version simple buffer est déjà faite, on va optimiser notre scrolling pour le rendre "compatible" avec le double buffer, et conserver une vitesse d'exécution largement suffisante pour n'importe quel de vos projets.
Comment ?
Et si on regardait quel temps machine prend notre scrolling? Une première méthode pour contrôler le temps machine d'une routine est de changer la couleur (par exemple du fond) et de laisser filer le temps de notre routine, puis de changer cette couleur en fin de calculs. Ainsi on a un premier résultat visuel (dans les limites de la visibilité, du temps max, etc.).
RMR2 ASICON : ld hl,#FA4 : ld (#6420),hl : RMR2 ASICOFF ld a,(OCTET_CURSEUR_BAS) : and BIT_CURSEUR_BAS : call z,ScrollBas ld a,(OCTET_CURSEUR_HAUT) : and BIT_CURSEUR_HAUT : call z,ScrollHaut ld a,(OCTET_CURSEUR_DROITE) : and BIT_CURSEUR_DROITE : call z,ScrollDroite ld a,(OCTET_CURSEUR_GAUCHE) : and BIT_CURSEUR_GAUCHE : call z,ScrollGauche RMR2 ASICON : ld hl,#000 : ld (#6420),hl : RMR2 ASICOFF |

Voilà illustré par la grosse bande verte, notre temps machine. Honnêtement, je m'attendais à bien pire que ça pour du code pédagogique.
Si on voit tout de suite que c'est le scrolling horizontal qui prend beaucoup de temps machine, on ne voit pas (même à la louche) le temps pris par le scrolling vertical. Comment faire?
Alors premièrement, on file dans la trace trouver nos routines de Scrolling et on va les encadrer par des points d'arrêt (oui, le code n'est pas exactement le même, j'ai automatisé les mouvements pour faire les gif animés)
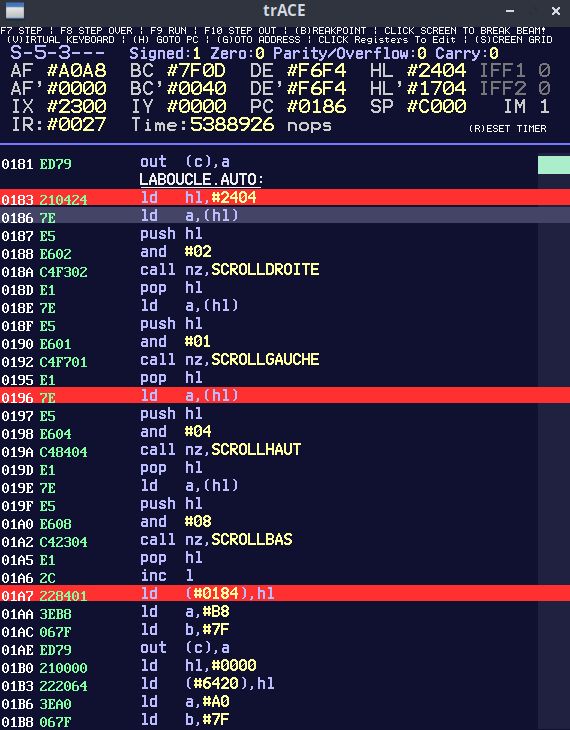
Pour activer le point d'arrêt, il suffit de cliquer sur les instructions (ou à gauche de l'instruction). On en active donc 3 pour avoir avant chaque partie et après.
Un clic DROIT dans la trace pour ouvrir le menu contextuel et demander la fenêtre des points d'arrêt (Breakpoints)
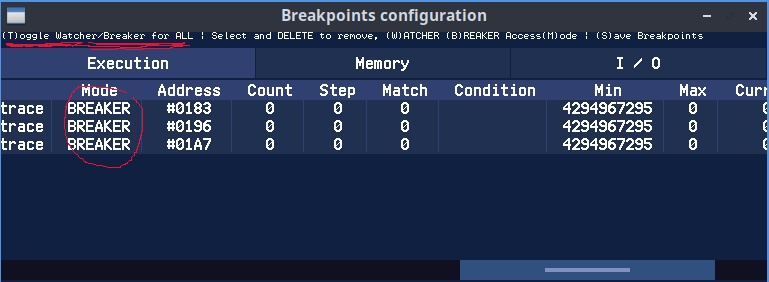
Nous avons 3 points d'arrêt en mode BREAKER avec une valeur Min éclatée au sol et un maximum à zéro, c'est normal :)
On appuie sur "T" pour passer nos 3 points d'arrêt en WATCHER, c'est à dire qu'ils ne vont pas stopper notre programme. Par contre ils vont compter le nombre de passages ainsi qu'un temps intermédiaire, ou plutôt, le nombre de NOPS écoulés depuis le dernier point d'arrêt (colonnes Min, Max et Current).
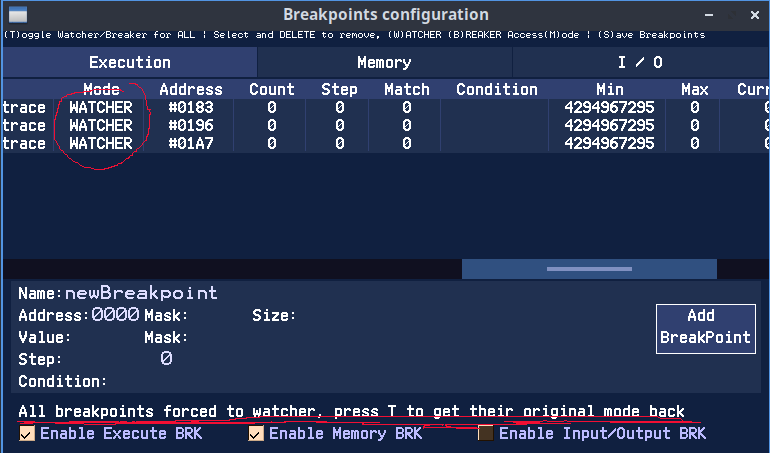
On relance le programme via F9 et on laisse tourner notre programme, ici 1159 fois.
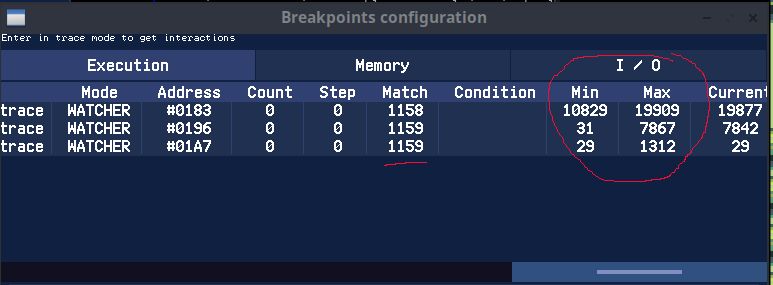
Cela sautait déjà aux yeux mais on a les valeurs précises et surtout maximales, le scrolling vertical prend 1312 nops au maximum tandis que le scrolling horizontal 7 fois plus!
Ça ne veut pas dire qu'on n'optimisera pas le scrolling vertical mais on sait où il faut concentrer nos effort pour gagner du temps machine (pour le moment, on ne bouge aucun sprite! On ne fait qu'un bête scrolling)
Quand on regarde notre routine, dans le cas clippé ou non, le temps se concentre sur l'affichage des tuiles non clippées et il y a...
...deux lignes!
ld bc,#1004 : .loopColumn ld a,(hl) : ld (de),a : call NextLineDE ld a,l : add c : ld l,a : djnz .loopColumn |
Quand on n'a pas d'idée, la méthode la plus simple va consister à tout dérouler, supprimer les compteurs et les CALL/RET. Donc ces deux lignes là...
Si on déroule le compteur et qu'on applique nos corrections d'adresses car on SAIT qu'on est aligné sur nos blocs, on répète 7 fois l'ajout de #800, puis on soustrait #3800 et on ajoute 64 sur les lignes multiples de 8, ce qui se résume en code assembleur par ceci : Évidemment, les répétitions automatiques de l'assembleur sont pratiques mais le code est quand même plus gros en mémoire.
ld bc,#0804repeat 7 : ld a,(hl) : ld (de),a : ld a,l : add c : ld l,a : ld a,d : add b : ld d,a : rendld a,(hl) : ld (de),a : ld a,l : add c : ld l,ald a,64 : add e : ld e,a : ld a,#C8 : adc d : ld d,a : res 3,drepeat 7 : ld a,(hl) : ld (de),a : ld a,l : add c : ld l,a : ld a,d : add b : ld d,a : rendld a,(hl) : ld (de),ald a,64 : add e : ld e,a : ld a,#C8 : adc d : ld d,a : res 3,d |
Après un petit tour dans le profiling, notre routine tombe déjà de 7800 à 3800 nops, on a plus que doublé la vitesse, sans changer nos données!
Est-ce qu'on pourrait gagner encore? Bien sûr! Mais pour faire quoi, et à quel prix* ? Dans la partie clippée, remplacer les CALL par une routine sur place (on parle aussi de code "inline")
MACRO expandNextLineDEld a,d : add 8 : ld d,a : and #38 : jr nz,@termineld a,64 : add e : ld e,a : ld a,#C0 : adc d : ld d,a : res 3,d@termineMEND |
Et on remplace les CALL par l'appel à la macro comme ci-dessous
.loopColumnC1 ld a,(hl) : ld (de),a : expandNextLineDE (void) : ld a,l : add c : ld l,a : djnz .loopColumnC1 |
On s'arrêtera ici pour ce côté (gain de 100 nops pour quelques octets, ça va).
Aller plus loin requiert des changements de données (et avoir deux fois les données graphiques, une version optimisée pour le tracé de lignes et l'autre pour le tracé de colonnes) pour gagner environ 25% de temps machine.
Le meilleure optimisation restante serait d'accroitre la complexité et scinder l'affichage de la colonne en deux. On divise le temps machine par deux si et seulement si les mouvements de scrolling sont faibles.
L'affichage des lignes horizontales mérite-t'il qu'on s'attarde sur lui?
J'ai envie de dire oui pour deux raisons, dont l'une découle de la première... Actuellement quand notre scrolling bouge d'un pixel à l'horizontal, le déplacement est deux fois plus grand qu'à la verticale car les pixels ne sont pas carrés!
Il faudrait harmoniser les vitesses de scrolling, sous peine d'avoir des effets secondaires visuels désagréables (Préhistorik 2 par exemple). Et si on double le nombre de lignes affichées à l'horizontale quand on bouge l'écran, on peut accélérer le calcul du rebouclage de bloc! En effet, il est plus simple si on sait qu'on est sur une ligne paire ou impaire!
Rebouclage de bloc sur n'importe quelle ligne
ld a,d : and %11111000 : inc de : ld c,a : ld a,d : and 7 : or c : ld d,a ; poussif non? Honnêtement j'ai pas cherché à faire mieux... |
Sauf que sur les lignes paires seulement, c'est beaucoup plus simple!
inc de : res 3,d |
Et sur les lignes impaires, un chouille plus long et contraignant (opération pré-incrémentation gêne le LDI(R)).
res 3,d : inc de : set 3,d |
On reprend notre code d'affichage des tuiles sur une ligne horizontale et on dédouble code. Une fois pour les lignes paires, une fois pour les lignes impaires.
Une nouvelle routine (afficheTuilesHorizontalesDeuxLignes) fait son apparition, elle va réutiliser le pointeur de tuiles dans HL' et le pointeur écran DE pour avoir la ligne suivante + facilement. Il faut aussi dédoubler les macros pour gérer le calcul sur la ligne du dessous. Je ne développe pas plus, ceci est une étape intermédiaire!
afficheTuilesHorizontalesPaires;-------------------------------ld a,(ix+multi.colonne) : or a : jp nz,.routineClippeecalculeAdresseTuileLigne 1 : ldi 4 : res 3,d.looprepeat 15calculeAdresseTuileLigne 1 : ldi 4 : res 3,drendret;-----------------.routineClippee;-----------------ld yh,15 ; on aura 15 sprites entiers et 2 sprites partielscalculeAdresseTuileLigneColonne 1ld a,4 : sub (ix+multi.colonne) : ld c,ald b,0 : ldir : res 3,dcall .loopcalculeAdresseTuileLigne 0ld c,(ix+multi.colonne)ld b,0 : ldir : res 3,dret;-------------------------------afficheTuilesHorizontalesDeuxLignes;-------------------------------exx : push hl : exxpush decall afficheTuilesHorizontalesPairespop de : ld a,d : add 8 : ld d,aexx : pop hl : exx;-------------------------------afficheTuilesHorizontalesImpaires;-------------------------------ld a,(ix+multi.colonne) : or a : jp nz,.routineClippeecalculeAdresseTuileLigneI 1 : ldi 3 : ld a,(hl) : ld (de),a : res 3,d : inc de : set 3,d.looprepeat 15calculeAdresseTuileLigneI 1 : ldi 3 : ld a,(hl) : ld (de),a : res 3,d : inc de : set 3,drendret;-----------------.routineClippee;-----------------ld yh,15 ; on aura 15 sprites entiers et 2 sprites partielscalculeAdresseTuileLigneColonneI 1ld a,4 : sub (ix+multi.colonne) : ld c,ald b,0 : ldir : dec de : res 3,d : inc de : set 3,dcall .loopcalculeAdresseTuileLigneI 0ld c,(ix+multi.colonne)ld b,0 : ldirret |
Avec ces modifications, on est déjà à 2100 nops pour deux lignes, au lieu de 1300 nops pour une ligne. C'est 250 nops de gagné par ligne, soit 20% de temps machine.
Est-ce qu'on peut faire mieux (sans que ça soit grotesque, n'oublions pas que nous faisons du code efficient. Passer des mois à gratter deux nops et rien sortir, on laisse ça aux autres).
La réponse est ouiiiiiiiiiiiiiiiiiii!
Ce qu'on remarque sur la routine ci-dessus, c'est qu'on va calculer deux fois l'adresse dans la tuile à la bonne ligne alors que la ligne suivante, une fois qu'on a affiché celle du dessus, on y est!
Comment réutiliser les adresses déjà calculées? On va réorganiser un peu notre source et en affichant les lignes paires, on va envoyer les adresses de tuiles des lignes impaires dans leur code d'affichage.
afficheTuilesHorizontalesDeuxLignes;-------------------------------push de.Pairesld a,(ix+multi.colonne) : or a : jp nz,.routineClippeecalculeAdresseTuileLigne 1 : ldi 4 : res 3,d : ld (suiteImpaire.imp0+1),hl ; adresse de la ligne suivante de la tuile à la bonne ligne.looprepeat 15,xcalculeAdresseTuileLigne 1 : ldi 4 : res 3,d : ld (suiteImpaire.imp{x}+1),hl ; adresse de la ligne suivante de la tuile à la bonne lignerendjp suiteImpaire.NonClippee;---------------.routineClippeecalculeAdresseTuileLigneColonne 1ld a,4 : sub (ix+multi.colonne) : ld c,a : ld (suiteImpaire.lenFirst+1),ald b,0 : ldir : res 3,dld a,(ix+multi.colonne) : add l : ld l,a : ld (suiteImpaire.impFirst+1),hl ; adresse de la ligne suivante de la tuile à la bonne colonnerepeat 15,xcalculeAdresseTuileLigne 1 : ldi 4 : res 3,d : ld (suiteImpaire.imp{x}+1),hl ; adresse de la ligne suivante de la tuile à la bonne lignerendcalculeAdresseTuileLigne 0ld c,(ix+multi.colonne)ld b,0 : ldir : res 3,dld a,4 : sub (ix+multi.colonne) : add l : ld l,a : ld (suiteImpaire.impLast+1),hl ; adresse de la ligne suivante de la tuile à la bonne colonnesuiteImpaire.clippeepop de : ld a,d : add 8 : ld d,a.impFirst ld hl,#1234.lenFirst ld c,#12ld b,0 : ldir : dec de : res 3,d : inc de : set 3,dcall .loop.impLast ld hl,#1234ld c,(ix+multi.colonne)ld b,0 : ldirret.NonClippeepop de : ld a,d : add 8 : ld d,a.imp0 ld hl,#1234 : ldi 3 : ld a,(hl) : ld (de),a : res 3,d : inc de : set 3,d.looprepeat 15,x.imp{x} ld hl,#1234 : ldi 3 : ld a,(hl) : ld (de),a : res 3,d : inc de : set 3,drendret |
Le calcul d'adresse d'une tuile est assez gourmand, plus de 30 nops dans notre cas. Avec la réutilisation d'adresse, on tombe à 8 nops (écrire dans le code et relire ensuite) et l'ensemble affichant les deux lignes est chronométré à...
Moins de 1400 nops, en fait très proche du temps qu'il nous fallait au début pour afficher une seule ligne!
On n'oubliera pas de modifier les routines ScrollHaut et ScrollBas pour passer de deux lignes en deux lignes!
Pas de code source complet, ça fait la même chose qu'hier, on va plutôt voir comment utiliser notre structure d'affichage pour faire le double buffer dans [ l'article suivant ]