Division 32 bits en assembleur Z80
Le Z80 est un processeur 8 bits, il n'est pas capable de réaliser nativement des divisions ou des multiplications. Avant d'écrire cet article, j'ai parcouru l'ensemble des sites que je connaissais fournissant des morceaux de code Z80 et si on trouve des routines étendues pour la multiplication, c'est plus compliqué pour la division.
Sur le site Quasar on trouvera un déroulé visuel de la méthode "naïve" de division. La même que celle qu'on réaliserait à la main, mais en base 2 !
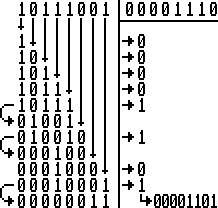
La méthode proposée s'applique bien à de petits nombres, ce n'est pas la plus optimisée qu'on puisse trouver, voir la page Annexe sur les divisions.
division 8 x 8 non signée => C
e_divise_par_d ; résultat dans le registre C ld b,8 xor a ld c,a .loop sla e rla cp d jr c,.skip sub d .skip ccf rl c djnz .loop ret |
Par contre on se rend vite compte que chaque itération nécessite 3 variables à décaler, une comparaison (une soustraction qui n'affecte pas le résultat) et éventuellement une soustraction, soit 5 manipulations de variables par bit.
Il est possible d'éclater l'algorithme pour réduire le nombre d'opérations logiques à effectuer.
Plutôt qu'itérer sur le dividende et le diviseur, on va décaler notre diviseur jusqu'à ce qu'il dépasse le dividende. Cela va nous donner le nombre d'opérations à réaliser pour notre division. La complexité de cette préparation utilise 2 manipulations de variable jusqu'au bit maximum utile.
div32unsigned; (IX) : dividende; (IY) : diviseur; limitation connue => diviseur sur 31 bits max ; on veut trouver la quantité max d'itérations à réaliser xor a : ld de,(iy+0) : ld bc,(iy+2) jr .firstIterationQbit .findMaxQbit sla de : rl bc ; x2 .firstIterationQbit inc a : ld hl,(ix+0) : or a : sbc hl,de : ld hl,(ix+2) : sbc hl,bc : jp nc,.findMaxQbit cp 1 : jr z,.noadjust : srl bc : rr de : dec a : .noAdjust |
Par exemple, pour la division de 153 / 13 nous aurons :
- 13 non décalé = 13
- 13 << 1 = 26
- 13 << 2 = 52
- 13 << 3 = 104
- 13 << 4 = 208 (on dépasse le dividende, stop)
Il faut s'arrêter à la 4è itération.
Ensuite nous passons à la partie de calcul du quotient. En 4 itérations :
| Itération | Diviseur décalé | Peut-on soustraire? | Reste | Bit du quotient - Peut-on soustraire? (bis) |
|---|---|---|---|---|
| 0 | 104 | Oui | 153 - 104 = 49 | Bit 3 = 1 |
| 1 | 52 | Non | 49 ne bouge pas | Bit 2 = 0 |
| 2 | 26 | Oui | 49 - 26 = 23 | Bit 1 = 1 |
| 3 | 13 | Oui | 23 - 13 = 10 | Bit 0 = 1 |
Vérification : Notre quotient vaut 11. 11 x 13 = 143, reste bien 10 pour atteindre 153
Et voici le code de la deuxième partie de l'algorithme
; d'abord initialiser nos variables pour utiliser au "maximum" les registres
push bc : exx : pop de : exx ; load diviseur in DE':DE
ld hl,(ix+0) : ld (remainder),hl : ld hl,(ix+2) : ld (remainder+2),hl ; initialise temp remainder
ld hl,0 : ld (quotient),hl : ld (quotient+1),hl ; initialize quotient
; itérer en base 2 sur la division
ld b,a
jr .firstIteration ; on décale notre quotient sauf au premier passage :)
.computeQuotient
ld hl,(quotient) : add hl,hl : ld (quotient),hl : ld hl,(quotient+2) : adc hl,hl : ld (quotient+2),hl ; shift quotient
.firstIteration
or a : ld hl,(remainder) : sbc hl,de : exx : ld hl,(remainder+2) : sbc hl,de : exx : jp c,.bit0 ; cannot substract => 0
; si on peut soustraire, alors on applique au reste sinon il "reste" tel que pour la prochaine itération
exx : ld (remainder+2),hl : exx : ld (remainder),hl
ld a,(quotient) : or 1 : ld (quotient),a ; marquer le bit "peut-on faire la soustraction"
.bit0
srl de : exx : rr de : exx ; shift diviseur
djnz .computeQuotient
ret
defi remainder 0
defi quotient 0
|
La deuxième passe réalise 3 opérations logiques sur nos variables, 2 décalage et une soustraction. Mais alors, quel est le gain rapport à l'algorithme précédent? Il est à trouver du côté de la sortie rapide. Notre division 32 bits s'exécutera d'autant plus rapidement que le quotient (le résultat) est petit. Comme on manipule des données conséquentes (32 bits), éclater l'algorithme permet aussi de mieux utiliser les registres.
Cette version est un premier jet destiné à un but pédagogique sur les décalages.
Dans les [ resources ], j'ai optimisé le code pour ne plus utiliser de variables en mémoire, utiliser presque tous les registres, la routine est beaucoup plus rapide, plus courte et avec les explications de cet article, elle sera j'espère plus claire pour vous.